다중행함수(Multi-Row Function)
여러 행의 그룹에 대해 적용되는 함수
다중행 함수의 종류
그룹함수(Group Function)
집계함수(Aggregate Function) : COUNT, SUM, AVG, MAX/MIN
고급 집계함수 : ROLLUP, CUBE, GROUPING SETS
윈도우 함수(Winodw Function)
집계함수 >> 전체의 통계를 낸다고 생각해라
여러 행의 그룹에 대한 연산을 통해 하나의 결과를 반환함
SELECT, HAVING, ORDER BY 절에 사용 가능
GROUP BY 절을 통해 그룹핑 기준 명시
NULL을 제외하고 계산
100명 중 10명의 성적이 NULL일 때, 전체 평균을 90명에 대한 평균
"NULL 값은 없다고 생각"
입력행 전체가 NULL인 경우만 결과값이 NULL
(DISTINCT | ALL) - Default 는 All
"동일한 값을 가진 데이터를 하나의 값으로? 여러 값으로?"
DISTINCT : 같은 값을 갖는 여러 데이터를 한 건으로 간주

*MAX / MIN 관련 : 문자는 알파벳 순서, 날짜는 과거→현재 순서
GROUP BY
집계 함수는 일반적으로 GROUP BY 절을 사용하여 그룹별 연산 수행
소그룹별 집계시 GROUP BY 사용
SELECT POSITION, COUNT(*) 전체행수, COUNT(HEIGHT) 키건수, ROUND(AVG(HEIGHT), 2) 평균키
FROM PLAYER
GROUP BY POSITION;

"그룹의 기준이 되는 컬럼과 집계함수 외의 단일칼럼이 오면 ERROR 발생"
테이블 전체가 하나의 그룹인 경우 GROUP BY 생략 가능
SELECT COUNT(*) 전체행수, COUNT(HEIGHT) 키건수, ROUND(AVG(HEIGHT), 2) 평균키
FROM PLAYER;

"COUNT, AVG 가 쓰이면 무적권 집계함수다~"
GROUP BY ~ HAVING ~
포지션 별 키의 평균 출력
SELECT POSITION, ROUND(AVG(HEIGHT), 2) 평균키
FROM PLAYER
GROUP BY POSITION;

집계함수에 조건을 부여하는 경우
예) 포지션별 키의 평균이 180 이상인 경우만 출력
WHERE 절 사용 → ERROR
WHERE 절이 GROUP BY 절보다 먼저 수행되기 때문
SELECT POSITION, ROUND(AVG(HEIGHT), 2) 평균키
FROM PLAYER
WHERE AVG(HEIGHT) >= 180
GROUP BY POSITION;
→ERROR

집계의 조건은 HAVING 절에서 정의
예) 포지션별 키의 평균이 180 이상인 경우만 출력
SELECT POSITION, ROUND(AVG(HEIGHT), 2) 평균키
FROM PLAYER
GROUP BY POSITION
HAVING AVG(HEIGHT) ≥ 180;

그룹핑 기준이 2개인 경우
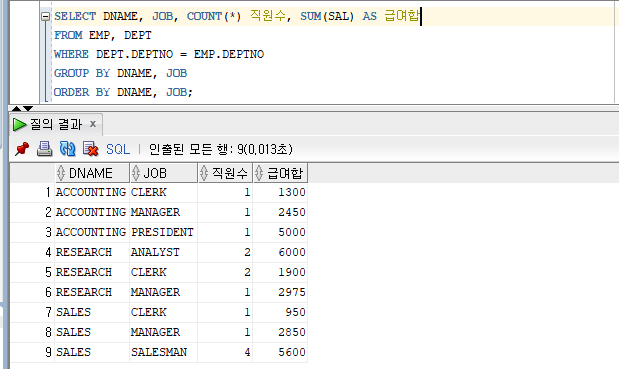
SELECT DNAME, JOB, COUNT(*) 직원수, SUM(SAL) AS 급여합
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME, JOB
ORDER BY DNAME, JOB;
SELECT 문장 구조
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
실제 실행 순서
FROM(질의 대상 테이블 참조) → WHERE(반환 대상이 아닌 데이터 제거) → GROUP BY(행 그룹화) → HAVING(반환 대상이 아닌 그룹 제거) → SELECT(데이터 값 계산 및 출력) → ORDER BY(출력 데이터 정렬)
ROWNUM 활용 시 주의사항
ROWNUM을 사용한 TOP N 쿼리
예) 키가 가장 작은 3명의 선수 조회
SELECT PLAYER_NAME, HEIGHT, ROWNUM
FROM PLAYER
WHERE ROWNUM < 4
ORDER BY HEIGHT;
→원하는 정보를 출력할 수 없음 : WEHRE문이 ORDER BY문보다 먼저 수행되기 때문

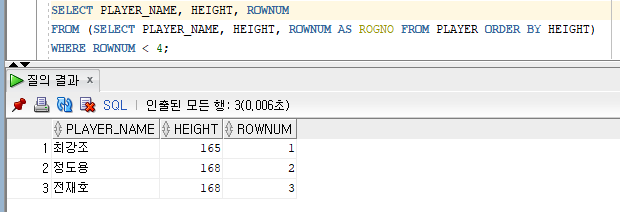
SELECT PLAYER_NAME, HEIGHT, ROWNUM
FROM (SELECT PLAYER_NAME, HEIGHT, ROWNUM AS ROGNO FROM PLAYER ORDER BY HEIGHT)
WHERE ROWNUM < 4;
칼럼의 유효 범위
관계형 데이터베이스는 데이터를 행 단위로 메모리에 복사함
SELECT 절에서 명시되지 않은 칼럼도 WHERE, ORDER BY 절에서 사용 가능
SELECT PLAYER_NAME, HEIGHT
FROM PLAYER
WHERE POSITION = 'MF'
ORDER BY TEAM_ID;

GROUP BY 가 사용되는 경우
SELECT 절에서 명시되지 않은 집계 칼럼을 HAVING, ORDER BY 에 사용가능
SELECT TEAM_ID, COUNT(*) 인원
FROM PLAYER
GROUP BY TEAM_ID
HAVING AVG(HEIGHT) > 178
ORDER BY AVG(HEIGHT);

인라인뷰 (Inline View)가 사용되는 경우
"인라인 뷰를 거치고 나면 새로운 테이블 구조가 생성된 것으로 이해해야 함"
인라인 뷰의 SELECT 절에 명시되지 않은 칼럼은 메인 쿼리에서 사용 불가
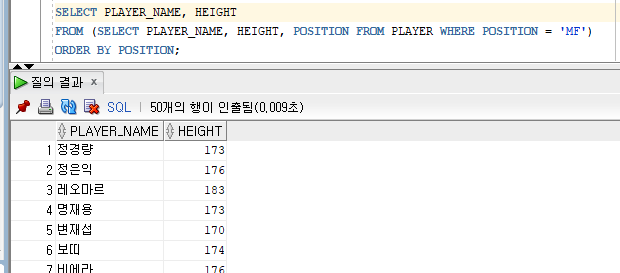
SELECT PLAYER_NAME, HEIGHT
FROM (SELECT PLAYER_NAME, HEIGHT FROM PLAYER WHERE POSITION = 'MF')
ORDER BY POSITION;
→ ERROR!!

SELECT PLAYER_NAME, HEIGHT
FROM (SELECT PLAYER_NAME, HEIGHT, POSITION FROM PLAYER WHERE POSITION = 'MF')
ORDER BY POSITION;
고급 집계 함수
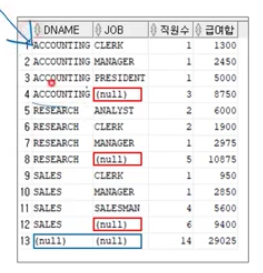
ROLLUP
소그룹 별 소계 계산 추가 ( 순서 중요 ) → 앞에꺼를 기준으로 소그룹 집계
각 DNAME/JOB 별 집계
각 DNAME별 집계
전체 집계
SELECT DNAME, JOB, COUNT(*) 직원수, SUM(SAL) AS 급여합
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB) *DNAME을 기준으로 소그릅 집계
ORDER BY DNAME, JOB;
SELECT DNAME, JOB, COUNT(*) 직원수, SUM(SAL) AS 급여합
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB, MGR)
ORDER BY DNAME, JOB, MGR;

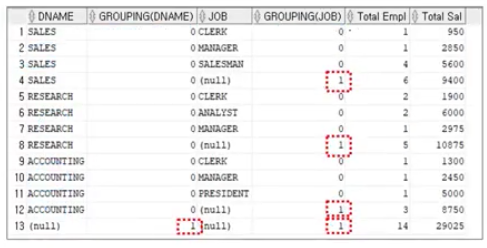
GROUPING 함수의 사용(SELECT문에 사용)
"어디까지 집계(그룹화)된 것이다.."를 알려주는 함수
SELECT DNAME, GROUPING(DNAME), JOB, GROUPING(JOB), COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB);
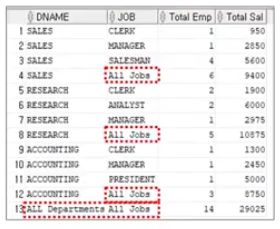
GROUPING + CASE 사용
"집계된 부분에 원하는 문구를 사용해서 보기 편하게 사용!"
SELECT
CASE GROUPING(DNAME) WHEN 1 THEN 'ALL DEPARTMENTS' ELSE DNAME
END AS DNAME,
CASE GROUPING(JOB) WHEN 1 THEN 'ALL JOBS' ELSE JOB
END AS JOB,
COUNT(*) "TOTLA EMP", SUM(SAL) "TOTAL SAL"
FROM EMP, DEPT WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB);
CUBE
다차원 소계 계산 추가 ( 순서무관)
모든 조합의 집계 계산 → 시스템 부하가 큼
SELECT DNAME, JOB COUNT(*) 직원수, SUM(SAL) 급여합
FROM EMP, DEPT
WEHRE DEPT.DETPNO = EMP.DEPTNO
GROUP BY CUBE (DNAME, JOB) *DNAME과 JOB 순서 상관 없이 같은 결과 출력
ORDER BY DNAME, JOB;
=
SELECT DNAME, JOB COUNT(*) 직원수, SUM(SAL) 급여합
FROM EMP, DEPT
WEHRE DEPT.DETPNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB)
UNION
SELECT DNAME, JOB COUNT(*) 직원수, SUM(SAL) 급여합
FROM EMP, DEPT
WEHRE DEPT.DETPNO = EMP.DEPTNO
GROUP BY ROLLUP (JOB, DNAME)
ORDER BY DNAME, JOB;
GROUPING SETS
여러 칼럼 각각에 대해 반복적으로 그룹화
SELECT DNAME, JOB COUNT(*) 직원수, SUM(SAL) 급여합
FROM EMP, DEPT
WEHRE DEPT.DETPNO = EMP.DEPTNO
GROUP BY GROUPING SETS (DNAME, JOB)
"DNAME으로만 집계, JOB으로만 집계하겠다>> 소계만 남기는 것"

GROUPING + DECODE 사용
"집계된 부분에 원하는 문구를 사용해서 보기 편하게 사용!"
SELECT
DECODE(GROUPING(DNAME), 1, 'ALL DEPARTMENTS', DNAME) AS DNAME,
DECODE(GROUPING(JOB), 1, 'ALL JOBS', JOB) AS JOB,
COUNT(*) 사원수, SUM(SAL) 급여합
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY GROUPING SETS (DNAME, JOB)
GROUP BY 와 UNION ALL 을 사용한 GROUPING SETS 구현

중요!

윈도우 함수 >> 전체 중 나!의 값 이라고 생각.
기존 관계형 DB는 칼럼간 연산은 쉽지만 행간의 연산은 어려움
행 간의 관계 정의를 위해 윈도우 함수 고안
예) 각 직원이 속한 부서 내에서 급여 순위는?
중첩(Nested) 사용 불가
서브쿼리에서도 사용 가능
종류
순위 - RANK, DENSE_RANK, ROW_NUMBER
집계 - SUM, MAX, AVG, COUNT
행 순서 - FIRST_VALUE, LAST_VALUE, LAG, LEAD
비율 - RATIO_TO_REPORT, PERCENT_RANK, NTILE
통계 - CORR, STDDEV, VARIANCE 등
SELECT WINDOW_FUNCTION (ARGUMENTS) OVER ( [PARTITION BY 칼럼] [ORDER BY 절] [WINDOWING 절] )
FROM 테이블 명;
WINDOW_FUNCTION : 기존 함수 OR 윈도우 함수로 추가된 함수
ARGUMENTS (인수) : 함수에 따라 0~N개의 인수 지정
PARTITION BY 절 : 전체 집합을 기준에 의해 소그룹으로 나눌 수 있음 "해당 칼럼 안에서~"
ORDER BY 절 : 순서를 지정할 기준 항목
WINDOWING 절 : 함수의 대상이 되는 행 기준의 범위를 지정
ROWS/RANGE 중 하나를 선택하여 사용
ROWS : 행의 수를 기준으로 한 범위
RANGE : 값을 기준으로 한 범위
WINDOWING 절의 사용 예
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING : 해당 파티션 내에서 앞의 한 행, 뒤의 한 행을 범위로 지정 RANGE BETWEEN 50 PRECEDING AND 150 FOLLOWING : 해당 파티션 내에서 현재 행의 값 -50 ~ 현재 행의 값 + 50 을 범위로 지정
RANGE UNBOUNDED PRECEDING : 해당 파티션의 첫 행부터 현재행까지 지정
순위 윈도우 함수
RANK 함수
동일한 값에는 동일한 순위 부여
동일한 순위를 여러 건으로 취급
예) 1등이 2명인 경우 → 1등 1등 3등
전체 급여 순위, JOB 내에서 급여 순위 출력
SELECT JOB, ENAME, SAL,
RANK() OVER (ODER BY SAL DESC) AS ALL_RANK,
RANK() OVER (PARTITION BY JOB ORDER BY SAL DESC) AS JOB_RANK
FROM EMP;
RANK, DENSE_RANK, ROW_NUMBER 비교
RANK 함수
동일 값에 동일 순위 부여
동일 순위를 여러 건으로 취급 (1등 1등 3등)
DENSE_RANK 함수
동일 값에 동일 순위 부여
동일 순위를 한 건으로 취급 (1등 1등 2등)
ROW NUMBER
동일 값에 다른 순위 부여 (1등 2등 3등)

MAX/MIN
각 직원이 속한 직업 내에서 급여의 최대값을 함께 출력하기 위한 질의
SELECT JOB, ENAME, SAL, MAX(SAL) OVER (PARTITION BY JOB) JOB_MAX
FROM EMP
ORDER BY JOB, ENAME;
*PARTITION 부분을 비워 놓으면 전체 데이터에서 출력 가능
SUM / AVG
각 직업 내에서 본인보다 높은 급여를 받는 직원의 급여 총합(본인 포함)
SELECT JOB, ENAME, SAL, SUM(SAL) OVER (PARITITION BY JOB ORDER BY SAL DESC RANGE UNBOUNDED PREDEDING) AS JOB_SUM
FROM EMP;
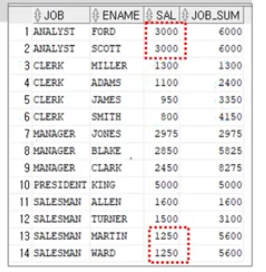
*값이 동일한 경우 동시에 반영( 나란히 있다고 생각)
각 직업 내에서, 본인 바로 위 + 본인 + 바로 아래의 급여 합 출력
SELECT JOB, ENAME, SAL, SUM(SAL) OVER (PARTITION BY JOB ORDER BY SAL ASC ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS JOB_SUM
FROM EMP;

COUNT
본인보다 급여가 100 적은 직원부터 200 많은 직원까지의 총 직원 수
SELECT ENAME, SALM COUNT(*) OVER (ORDER BY SAL RANGE BETWEEN 100 PRECEDING AND 200 FOLLOWING) AS MOV_COUNT
FROM EMP;
*DESC ASC 표기 안하면 ASC(낮→높)이 DEFAULT

행 순서 윈도우 함수
FIRST VALUE ( or LAST_VALUE) 함수
각 파티션에서 가장 먼저 ( 또는 나중) 나온 값
Q) 다음은 어떤 기능을 수행하는 질의인가?
SELECT DEPTNO, ENAME, SAL, FIRST_VALUE(ENAME) OVER (PARTITION BY DEPTNO ORDER BY SAL DESC, ENAME ASC) AS RICH_EMP
FROM EMP;
"파티션 내에서 샐러리 내림차순, 이름 오름차순으로 정리하고, 제일 먼저 나오는 ENAME을 뽑아라"
LAG ( or LEAD) 함수
각 파티션에서 해당 행의 몇 번째 이전 ( 또는 이후 ) 행의 값을 가져옴
Q) JOB ='SALEMAN'인 모든 직원에 대하여 급여 기준 본인 바로 윗 사람의 급여와 아랫 사람의 급여를 출력하는 질의 완성
LAG(SAL, 1) = LAG(SAL)
"나보다 1 앞에 있는 직원의 급여를 가져와라 (1이 DEFAULT)"
LEAD(SAL, 1) = LEAD(SAL)
"나보다 1 뒤에 있는 직원의 급여를 가져와라 (1이 DEFAULT)"
SELECT ENAME, SAL, LAG(SAL) OVER (PARTITION BY JOB ORDER BY SAL DESC) AS HIGHER_SAL, LEAD(SAL) OVER (PARTITION BY JOB ORDER BY SAL DESC) AS LOWER_SAL
FROM EMP
WHERE JOB = 'SALESMAN';
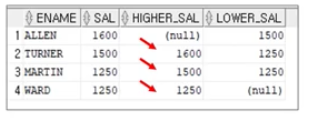
LAG(SAL, 2, 0) "앞에 2개 가져오고 빈칸은 0으로 채워라"
2번째 앞의 행을 가져오고 가져올 행이 없는 처음 두 행의 값은 0으로 채움
'0'을 생략하면 해당 두 행은 NULL 로 표시됨
비율 윈도우 함수
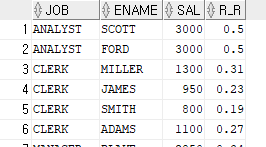
RATIO_TO_REPORT 함수
파티션 내 전체 SUM(칼럼) 값에 대한 행별 백분율
예) 동일 JOB 내에서 본인의 급여가 차지하는 비율 출력
SELECT JOB, ENAME, SAL, ROUND(RATIO_TO_REPORT(SAL) OVER (PARTITION BY JOB), 2) AS R_R
FROM EMP
OEDER BY JOB;
PERCENT_RANK 함수(가장 많이 쓰임)
행의 순서별 백분율을 구함
가장 먼저 나온 행 = 0 가장 나중 나온 행 = 1
예) 동일 JOB 내에서 본인의 급여가 상위 몇 %에 있는지 출력
SELECT DEPTNO, ENAME, SAL, 100*(PERCENT_RANK() OVER (PARTITION BY DEPTNO ORDER BY SAL DESC)) || '%' AS P_R
FROM EMP;

CUME_DIST 함수(누적분포)
현재 행에 대해 현재 행보다 작거나 같은 건수에 대한 누적 백분율
0 초과 1이하의 값을 가짐
*동일값은 큰 백분율을 적용!
→결과표를 보고 PERCENT_RANK인지 CUME_DIST인지 구분 할 수 있어야 함 (0으로 시작하는지 아닌지로)
NTILE 함수
파티션별 전체 건수를 N등분한 결과를 구함
Q) 전체 사원을 급여 순으로 정렬하고, 급여 기준 4개의 그룹으로 분리하는 질의를 작성
SELECT ENAME, SAL, NTILE(4) OVER (ORDER BY SAL DESC) AS 급여구간
FROM EMP;
*딱 안나눠 떨어지는 경우 남은걸 위에서부터 하나씩 다시 채워준다

'SQLD' 카테고리의 다른 글
| [SQL 기본과 활용] Subquery(★★★) (0) | 2021.04.08 |
|---|---|
| [SQL 기본과 활용] Join_Set Operation(★★★) (0) | 2021.04.07 |
| [SQL 기본과 활용] TCL/DCL (0) | 2021.04.02 |
| [SQL 기본과 활용] Function (0) | 2021.03.29 |
| [SQL 기본과 활용] DDL (0) | 2021.03.29 |




댓글